
Google 最新發表的 TurboQuant 壓縮技術,被視為削弱 AI 對高階記憶體依賴、衝擊記憶體廠「漲價邏輯」的重要變數。在華爾街和科技圈的解讀中,這很可能是拉低伺服器用 DRAM 成本、甚至壓縮 RAM 價格談判空間的關鍵一步。

TurboQuant 是甚麼?
Google Research 公布名為 TurboQuant 的全新量化/壓縮演算法,用來大幅壓縮大型語言模型(LLM)的記憶體佔用,同時維持模型準確度零損失。TurboQuant 會搭配 Quantized Johnson–Lindenstrauss(QJL)與 PolarQuant 等方法,針對向量與 KV cache 做極端壓縮,專門解決現今 AI 模型在記憶體上的龐大開銷問題。
記憶體需求少 6 倍
在大型語言模型中,最吃記憶體的關鍵元件之一是用來長上下文推理的 key-value(KV)快取;Google 指出 TurboQuant 可以把 KV cache 壓到僅 3 bits,記憶體需求至少縮小 6 倍,同時不犧牲下游任務準確度。在 Nvidia H100 GPU 的實測中,4-bit TurboQuant 在計算注意力 logits(attention logits)時,相比 32-bit 未量化版本,不但 KV 記憶體需求縮減至少 6 倍,還能將計算效能提升最高達 8 倍。
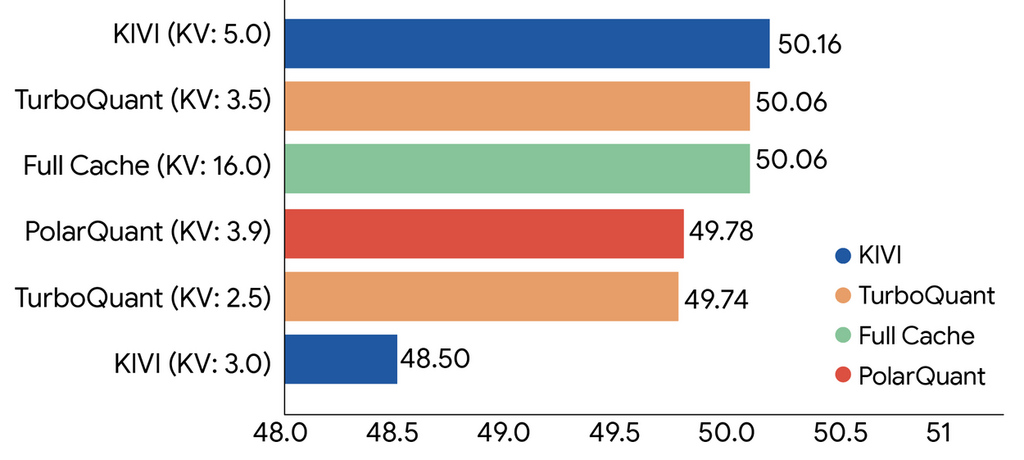
怎樣做到「極端壓縮但零準確度損失」?
TurboQuant 先透過 PolarQuant 對高維度向量做隨機旋轉,讓資料幾何結構變得更「規整」,再對各部分獨立套用標準高品質量化器,用大部分 bit 數來保留向量的主體訊息。接著再透過 QJL 等技術,在已壓縮的空間內進一步做幾何近似,達到更高壓縮率,同時仍維持向量檢索與注意力計算所需的距離關係,實現「高壓縮、低失真」的近似最佳狀態。
「RAM 價要跌」還是「成長趨勢放緩」
由於 TurboQuant 直接作用在 AI 推論最吃 RAM 的部分(KV cache、向量索引),一旦大規模導入,等於讓同一台伺服器可以「用更少記憶體跑更多模型」,市場自然開始質疑高階 HBM / DDR 記憶體的成長想像。
消息公布後,亞洲與美股多檔記憶體與儲存概念股出現明顯賣壓,市場擔心雲端與資料中心業者未來在擴充 AI 伺服器時,對 DRAM 容量的需求不再線性成長,削弱記憶體晶片廠手上的定價權。
