
OpenAI 今年先後推出兩個 AI 代理服務,最新又加推 ChatGPT Agent,將 AI 代理技術再推近通用人工智能(AGI)。OpenAI 指出,ChatGPT Agent 為用戶工作,而不再僅回應。ChatGPT Agent 具備思考能力,輸入任務內容便可自動完成,包括個人任務或辦公都可代勞,釋出更多時間好好生活。
ChatGPT Agent 結合原本的 AI 代理,包括 Operator 和 Deep Research,成為統一的代理系統,具備行動力和分析能力。
快至 5 分鐘完成複雜任務
由 OpenAI 提供的 ChatGPT Agent 用途甚為廣泛。例如早上由 ChatGPT 檢視當天的行事曆,找出當日的會議行程,撰寫報告簡介會議對象,如從網頁搜尋企業近期消息。
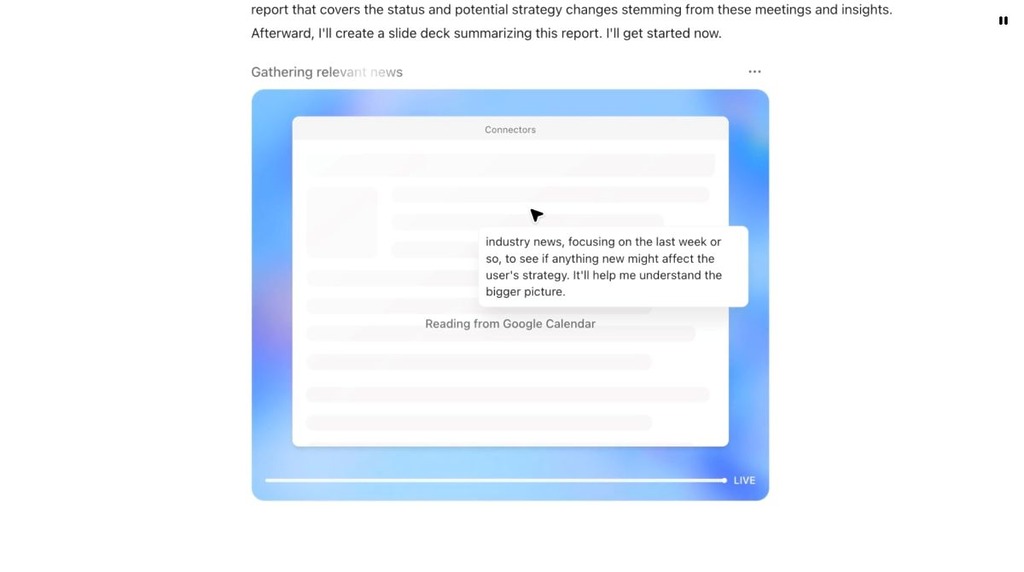
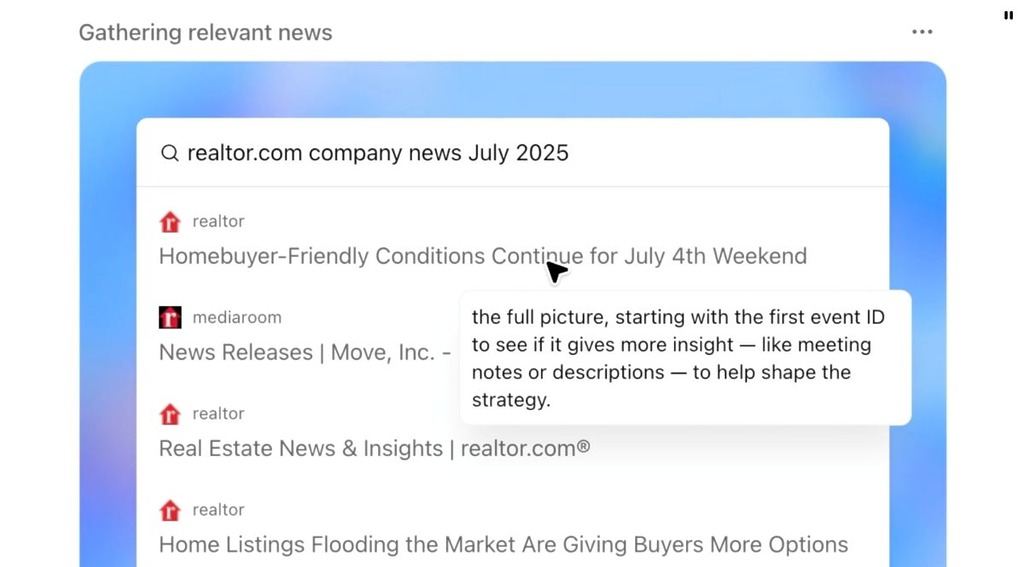
OpenAI 又提供更實際的參考例子:
- 籌劃活動:叫 ChatGPT 規劃 100 人的品牌見面會,列出各項預算和活動流程。然後,ChatPGT 會分拆成多個任務,先找出可容納 100 人的場地,推出建議。接著撰寫流程、物資,提供預算成本。
- 市場分析:給 ChatGPT 上傳 3 間公司產品報告的文件,可以包括圖表和文字,由 AI 代理分析,比較各產品之間的相同和差異,製作表格逐點比較。
- 個人消費選擇:考慮健身室服務,向 ChatGPT 提供幾間選項的資料,為用戶逐一比較收費和服務內容。甚至可以按位置和對用戶而言的交通方便程度去建議。
OpenAI 指出,收到指示後,背後分拆成多個小型任務,通常可以在 5 分鐘至 25 分鐘完成。用戶輸入指示,ChatGPT Agent 自動執行。有些任務甚至可以生成投影片。

整合不同工具
ChatGPT Agent 可運用多項工具去擷取資訊和執行任務,如:
- 視覺瀏覽器:仿效人類瀏覽網站,又能點擊連結、填寫表格等動作;
- 文字瀏覽器:擷取網頁文字內容,處理大量文本數據;
- 終端機:執行程式碼或指令碼,批量處理數據;
- API:與其他系統取得資訊,甚至提供數據更新彼方的內容;
- 安全登入及接管:由用戶授權安全地登入,讓代理通過身分驗證去完成任務。
處理複雜任務能力超越前一代
OpenAI 同時公開 ChatGPT Agent 的基準測試數據,顯示能力超越了前代模型,更遠高於人類表現。測試包括:
- Humanity’s Last Exam(HLE):在「單次通過率」得 41.6%,當採用「平行開展策略」,同時嘗試 8 次並選擇可信度最高的結果,得分更有 44.4%;
- DSBench:評估 AI 在數據分析的表現,得分超過人類,如「數據分析」準確度達到 87.9%,而人的結果則 64.1%,「數據建模」達到 77.1%,人類則 65.0%;
- SpreadsheetBench:評估模型編輯基於真實場景處理試算表的能力,得分 45.5%,遠勝 Copliot 處理 Excel 得分 20.0%;
- BrowseComp:衡量瀏覽代理尋找網絡上搜尋資訊的能力,寫下新 SOTA 的 68.9%,比 Deep Research 高出 17.4 個百分點;
- WebArena:評估網頁瀏覽代理完成網頁任務的能力。ChatGPT Agent 的表現更勝 Operator,準確度 78.2%,人類則 65.4%。
Pro 訂戶每月 400 次
ChatGPT Agent 用法如同「Deep Research」,在輸入欄下選「Agent」隨即啟用。 OpenAI 現時已開放 ChatGPT Agent 給 Pro、Plus 和 Team 方案訂戶,幾日內將可用。Enterprise 和 Edu 訂戶亦在幾個星期內可用。Pro 訂戶每月可執行 400 次 ChatGPT Agent,Plus 訂戶只有 40 次。
不過,瑞士或歐洲經濟區(European Economic Area, EEA)暫時未能使用這功能。當然,香港亦不能正式使用。
CEO 承認安全性仍有顧慮
不過 OpenAI CEO Sam Altman 表示 ChatGPT Agent 仍屬實驗性質,他在 X 表示,他們尚不清楚具體會造成什麼影響,但惡意分子可能會試圖「誘騙」用戶的 AI 代理提供不該提供的隱私信息,以進行不法行為。因此他們建議用戶只授予 ChatGPT Agent 完成任務所需的最低限度存取權限,以降低隱私和安全風險。
